前言
在写爬虫抓取信息的时候,需要对信息进行初步的整理,然后才落盘数据。这时候,我们需要用程序来将凌乱的数据先进行一次结构化,方便我们对数据进行写库。在这里分享一个简单数据整理技巧。
在进行分享前,先拿一个案例作为例子:
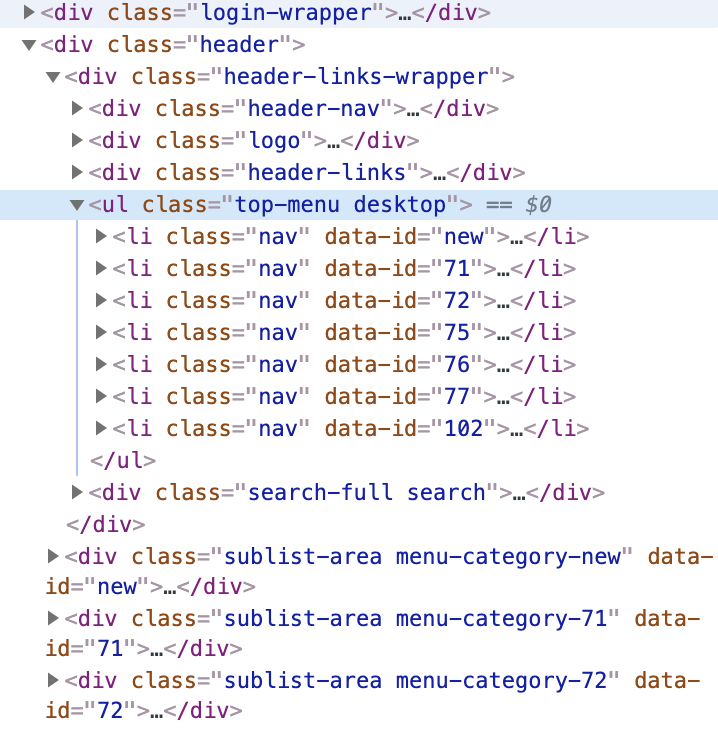
以某网站为例,这是一个目录表的网页结构,ul标签下为一级目录,每个目录有一个对应的id,下面的每一个div标签为该目录对应的子目录。那么我们应该如何去对这个目录结构进行一个结构化处理呢?
开始前,先介绍一下python的dict数据结构。因为这里爬虫使用的是python,所以我选择使用python下的dict结构对数据进行一个结构化的处理。
Dict字典
字典是python中能用关键字来查询相关内容的数据结构。它通过key-value键值对的形式来进行构建。因为在这个例子中,我们需要通过id来进行信息的匹配,选择使用字典的优势在于,字典存储起来可读性更强,最关键的地方,字典底层是通过hash实现的,如果我们以id作为key,那么在查询key的时候的时间复杂度为O(1),使用起来非常方便高效。具体字典的相关用法,这里就不详细介绍了,可以Google一下进行了解。
正文
Talk is cheap. Show me the code. 话不多说直接上代码。
-
Step one
首先我们使用一个数组来存储最终结构话的结果。(这里使用xpath对网页信息进行提取)
# define result list and cat2 dict result_list = list() cat2_dict = dict() cat_list = response.xpath('//div[@class="header"]/div') cat_1_list = cat_list[0].xpath('./ul[@class="top-menu desktop"]/li') for cat1 in cat_1_list: cat_1 = html.unescape(cat1.xpath('./a/text()').extract_first()) cat_1_url = urljoin(self.base_url, cat1.xpath('./a/@href').extract_first()) cat_1_id = cat1.xpath('./@data-id').extract_first() result_list.append({ 'cat_1': cat_1, 'cat_1_url': cat_1_url, 'cat_1_id': cat_1_id })OK, 完成对一级目录的信息存储。接下来的关键在于对二级目录的匹配存储。
-
Step two
在操作前,先思考一个问题。如何进行二级目录与一级目录的匹配。很显然我们需要用到一级目录中的id。那么这个时候dict中的key就发挥作用了。在抓取二级目录的时候,可以把每个二级目录的id作为一个key,然后用一个临时数组来存储该二级目录的全部信息,并把这个数组做为value与该key作为键值对形式存储下来。
for cat2_divs in cat_list[1:]: tmp_cat2_list = list() index = cat2_divs.xpath('./@data-id').extract_first() cat2_list = cat2_divs.xpath('.//ul[contains(@class, "sublist")]/li') for cat2 in cat2_list: cat_2 = html.unescape(cat2.xpath('./a/text()').extract_first()) cat_2_url = urljoin(self.base_url, cat2.xpath('./a/@href').extract_first()) tmp_cat2_list.append({ 'cat_2': cat_2, 'cat_2_url': cat_2_url }) cat2_dict.update({ index: tmp_cat2_list })好了,这一步完成以后,cat2_dict里面已经按照每个id及其对应的二级目录存储了所有的二级目录信息。
-
Step three
完成了一级目录和二级目录的存储,这时候就要把它们匹配起来,形成结构化的数据。
for item in result_list: index = item.get('cat_1_id') cat_2_list = cat2_dict.get(index) item.update({ 'cat_2_list': cat_2_list })
至此,对于这个网站的目录信息已经完成了结构化的处理,最终处理完成后的数据结构如下:
[ { 'cat_1': cat_1,
'cat_1_url': cat_1_url,
'cat_1_id': cat_1_id,
'cat_2_list': [ { 'cat_2': cat_2,
'cat_2_url': cat_2_url
},
...
]
}
...
]
处理完后,目录信息以JSON的格式存储了下来,那么在后期对数据进行落盘或其他处理的时候,就会方便很多了。这里的例子是个二级目录的例子,如果目录更加多层次,一样可以通过这种形式将其存储为JSON的格式。
整个方式处理下来,时间复杂度为O(1)。
结尾
对于各种各样纷繁复杂的数据信息,我们需要不断去学习和掌握对无序混乱的非结构化数据进行处理,方便我们后期对数据的存储和应用,后续会继续分享自己学习过程中的一些技巧。