跳跃表简介
跳跃表,是一种有序的数据结构,它相当于一个多层的链表,每个节点中维护多个指向其他节点的指针,从而达到快速访问节点的目的。跳跃表的查找操作平均时间复杂度为O(logN)。在大部分情况下,跳跃表的效率和平衡二叉树相当,并且跳跃表的实现更为简单。redis中的有序集合的底层实现,用的就是跳跃表,并且还在集群内部节点中也使用了跳跃表作为数据结构。
为什么会有跳跃表的出现(个人思考)
主要思考两个点:有序条件下查找和修改,即增删改查(数据库的特点,查找和修改操作非常频繁)
查找
常见的数据结构的查找,如数组,链表,二叉树,对于数组而言,采用的方式是二分,但是二分在链表中并不适用,主要有两点:一是因为链表的内存并不是连续的,我们无法快速地进行二分跳到中间的节点;其次要知道链表的长度必须先进行一次遍历,时间复杂度O(n),在查找的时候,我们都希望时间复杂度可以达到O(logN);对于二叉树而言,平衡二叉树可以很好地解决这个问题。
修改
对于链表而言,修改操作非常简单,只需要遍历一次链表,找到节点位置,即可以在O(1)时间复杂度的情况下完成修改,查找最坏情况也就是O(n);但是对于数组而言,修改起来就很麻烦,涉及到多节点的移动
在这个背景需求下,跳跃表的出现均衡了链表和数组。跳跃表通过多层链表的结构,可以实现类二分的查找,并且兼顾了链表修改的优点。
详细关于跳跃表的介绍,可以参考这篇文章
数据结构定义
这里阅读的是redis 5.0版本。
源码位置:
- server.h:zskiplistNode和zskiplist的数据结构定义;
- t_zset.c:Skiplist相关的操作函数;
redis中跳跃表的数据结构,包含两个部分:节点和组织方式,即zskiplistNode和zskiplist
typedef struct zskiplistNode {
sds ele; //数据域, sds类型
double score; //分值
struct zskiplistNode *backward; //后向指针,双向链表
struct zskiplistLevel { //每一个结点的层级
struct zskiplistNode *forward; //当前层的前向结点
unsigned int span; //当前层距离下一个结点的跨度
} level[]; //level本身是一个柔性数组,最大值为32,由 ZSKIPLIST_MAXLEVEL 定义
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header; //头部指针, 指向跳跃表的第一个节点
struct zskiplistNode *tail; //尾部指针,指向跳跃表最后一个节点
unsigned long length; //长度,即一共有多少个元素,除开header的长度
int level; //最大层级,即跳表目前的最大层级
} zskiplist;
了解完两个关键的数据结构定义以后,就是增删改查的一些相关操作了。代码中,最核心的部分是插入部分,这部分相对难以理解,把这部分的代码理解以后,其余的就很好理解了。
创建
创建部分的函数是zslCreate和zslCreateNode,看一下代码
/* Create a new skiplist. */
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl)); //申请空间
zsl->level = 1; //初始化层级为1
zsl->length = 0; //初始化长度为0
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL); //创建header节点,并且层数为ZSKIPLIST_MAXLEVEL
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
/* Create a skiplist node with the specified number of levels.
* The SDS string 'ele' is referenced by the node after the call. */
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
创建部分有一个重要的点,即header头节点;头节点不存储数据,可以理解为每层链表的起始点,通过头节点开始遍历等操作。
创建完成后,大致的zsl图示如下(借图):

图示很好理解,headers的层数为32,即跳表最多可容纳32层链表。
插入
插入部分是redis跳表实现中最关键的部分,根据作者的说法,与传统的跳跃表相比,redis中的跳跃表多了以下三个特点:
- this implementation allows for repeated scores. // 允许分值重复
- the comparison is not just by key (our ‘score’) but by satellite data. //在比较节点的时候,不仅对比分值还比较对象的值
- there is a back pointer, so it’s a doubly linked list with the back pointers being only at “level 1”. //有后退指针,形成双向链表,允许后退遍历
看一下代码部分:
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; //(1)
while (x->level[i].forward && //(2)
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x; //(3)
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel();
if (level > zsl->level) { //(4)
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward; //(5)
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); //(6)
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) { //(7)
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
在源码中,我标识了7个关键部分,先进行总结,插入过程步骤:
1) 通过从最高层开始的大跨度方式,找到插入位置,记录rank数组和update数组;
2)随机生成level,若level大于现有的层数,则初始化多出来的层;
3)创建新节点,插入节点,并更新跨度span;
4)更新未遍历过的层和zsl的相关值;
接下来,开始详细展开7个关键部分,在展开前,先理解两个关键的数组,rank和update,这两个数组弄清楚了,后面的代码过程就很好理解了。
- rank[]:rank[i]表示update[i]指向的节点的在跳跃表中的排位rank;
- update[]: update[i]表示第i层最接近所要插入的那个节点,存储的是节点地址;即插入节点第i层的前置节点;
为什么要用到这两个数组呢,因为我们知道链表的特点是,内存地址不连续,要进行修改操作,我们得知道修改位置的前置节点的地址,才能进行操作;update就是用来记录前置节点的地址,rank是用来记录前置节点的排位的;因为跳跃表的多层的,所以这两个变量使用数组。有人会问,redis的跳跃表是双向链表啊,为什么还要记录?问题就在于,backward指针指向的仅仅是上一个node的地址(可以理解为第0层链表的前一个节点,跳跃表的第0层就是一个普通的链表),但是并不是当前链表层的上一个node的节点。
可以借助一下图示来理解,还是借图:
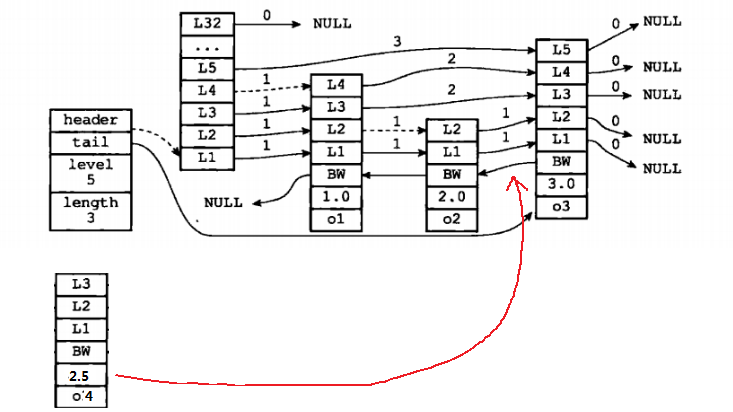
如图所示,红线表示要插入的节点,是要插入到o2和o3之间。在这个示例中,update[0]指向的是o2,update[1]也是o2, update[2]和update[3]指向的是o1,update[4:31]指向的是header节点。而rank[0]表示的是o2的rank,为2,即o2与header节点的间距,rank[1] = 2, rank[2] = rank[3]=1。
(1) 从最高层开始遍历, 赋值记录rank,如果(zsl->level-1)为i,即level为最高层,初始化rank为0,因为是从header节点开始遍历的。否则当前层的rank值为上一层的rank值;这里说一下为什么是rank[i] = rank[i+1],因为从跳跃表的遍历方式上出发,最高层开始遍历,如果没有继续forward,那么update[i]为这一层最后一个临近的节点,rank[i]为该节点的排位;然后开始下降一层继续遍历,到第i-1层,那么这时候指针指向的节点是同一个节点,rank[i]自然是等于rank[i+1]的,这样就在记录第i层临近节点排位的同时,省去了第i-1层再次遍历的步骤。
(2) 判断当前节点的分值和对象值,如果比插入值小,则向前遍历,rank值加上当前节点当前层到下一个节点的跨度,rank[i] += x->level[i].span;;
(3) 否则,记录遍历到的当前层的节点地址,下沉到下一层继续遍历;
(4) 如果随机出来的level比当前跳跃表的level要高,则初始化高出来的层,这里很好理解;
(5) 创建完新节点以后,开始插入的操作;链表的常规插入操作,先把新插入的节点链上下一个节点,再把新插入的节点链上;
(6) 这部分有点绕,比较难理解,涉及到的是span的计算和更新。这里展开来说一下:
-
rank[0]表示的是update[0]指向的节点的排位,该节点一定是插入节点的前置节点,因为上面说到了,第0层就是一个普通的链表;
-
rank[i]表示的是update[i]指向的节点的排位,该节点的level[i],即第i层的下一个节点指向的就是插入节点;
-
以插入节点x的下一个节点y在跳跃表中的排位rank,建立一个等式:rank[i]+update[i]->level[i].span+1 == rank[0]+1+x->level[i].span
等式左侧rank[i]为插入节点在第i层链表的前置节点的排位,加上该节点到y的跨度update[i]->level[i].span,再加上插入节点x占的一个位置1,就是节点y在跳跃表中的新排位;
等式右侧rank[0]为x在第0层的前置节点的排位,加上1就是x在第0层的排位,再加上x在第i层上到下一个节点y的跨度,最终也是等于节点y在跳跃表中的新排位。
其实就是从两个维度,第0层(单链表)和第i层链表上建立了这个等式。由这个等式可以得出`x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);`
update[i]->level[i].span = (rank[0] - rank[i]) + 1;插入节点x在第i层链表上的前置节点z到x的跨度,间距就等于x在第0层上的前置节点的排位,减去z的排位再加上1。rank[0] - rank[i]的值,为z到x在第0层的前置节点的span。
(7) 更新未遍历过的层级的节点的span跨度,因为插入了一个节点,所以直接加1就可以了。
剩余的部分很好理解,就是更新backward,tail和length,然后返回插入的节点的地址。